
numpy&pandas基础
ndim、shape、dtype、astype的用法
ndim:返回数组维度
shape:返回各个维度大小的元组,类似matlab的size
dtype:(data type)返回数据类型(例如:int32,float32)
astype:类型转化
eg:array.astype(“i”)
小转大,例如int32–>float64,没问题
大转小,例如float–>int32,会将小数部分截断
string_ –>float64 若字符串数组表示的为数字,将把字符串转为数值类型
数组拼接
np.concatenate( ) np.append( )
concatenate:n 连环,v 系、串联
append:附上,附加,增补
两个方法主要区别在于concatenate( )可以连接多个数组,而且多维数组的shape不需要完全相同;append( )只能连接2个,而且多维数组的shape必须相同
两方法同时有可选参数axis
axis=0 按照行拼接。 axis=1 按照列拼接。 不写则默认axis=0
a = np.array([1, 2])
b = np.array([5, 6])
c = np.array([3, 4])
np.concatenate((a,b,c))
结果:[1 2 5 6 3 4]
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]]) #b是一个二维array
np.concatenate((a, b), axis=0) #按照行拼接
array([[1, 2],
[3, 4],
[5, 6]])
np.concatenate((a, b.T), axis=1) #按照列拼接
array([[1, 2, 5],
[3, 4, 6]])
注:b.T的意思为b数组的转置
append的意思为附加、增补x行或者x列,仅用于两个矩阵之间
pandas数据结构series和dataFrame
-
pandas中主要有两种数据结构,分别是:Series和DataFrame。
-
Series:一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。注意:Series中的索引值是可以重复的。
-
eg:series创建
可以通过一维数组创建:
arr = np.array([1,3,5,np.NaN,10]) series01 = pd.Series(arr) #利用arr转化,注意Series大写,一般数据结构封装类首字母都是大写的
也可通过字典的方式创建
dict1 = pd.Series({ 'a':10, 'b':20, 'c':30 }) #通过字典的方式创建,key变成了Series的索引,value变成了值
-
eg:series索引
#索引可以创建series后再手动设置 series02 = pd.Series([1,2,3,4]) series02.index = ['a','b','c','d'] #也可在创建时同步设置 series03 = pd.Series(np.array([1,2,3,4]),dtype = np.float64,index = ['*','**','***','****'])

-
eg:series值获取
通过[] + 索引的方式读取对应索引的数据,有可能返回多条数据(series的索引可以重复)
通过[] + 下标值的方式读取对应下标值的数据,下标值的取值范围为[0,len(Series.values)],此外下标值也可以是负数,表示从右往左读取数据
Series的下标值和数组的“索引”才是对应的,而Series的索引更像是给数据value赋予的一个label(标签)
Series获取多个值的方式类似数组,通过[]+下标值/索引值+:的形式来截取对象中一部分数据,通过索引和下标值截取区间是不同的
#以series03为例 #通过索引读取: series03['*':'***'] #通过下标值读取: series03[0:2] -
eg:series的运算
#series运算与numpy的array类似 series03[series03>2] series03[series03/10] series03[np.exp(series03)] series03[np.fabs(seres03)] #fabs是float类型的abs,取绝对值 #series运算不会改变索引与value之间的对应关系 -
series缺失值检测
#所谓缺失值,例如pandas中的NaN,通常由于series创建时,未给索引赋值导致 series04 = pd.Series([10,20,30]) series04.index = ['a','b','c','d'] #这里赋值时有三个,而索引有四个,就会导致NaN的出现 #pandas提供了isnull和notnull函数可以用于series中检测缺失值,这两个函数返回一个布尔类型的Series,即索引与原Series一致,value值为布尔值类型 pd.isnull(series04) pd.notnull(series04) -
series自动对齐
# series05 = pd.Series({ 'num1':10, 'num2':20, 'num3':30 }) series06 = pd.Series({ 'num4':10, 'num2':20, 'num3':30 }) series05+series06 #相同索引下标会对齐,非公共索引计算会得出NaN
-
series及其索引的name属性
Series对象本身及其索引具有一个name属性,默认为空,根据需要可以赋值
series07 = pd.Series([1,2,3,4],index=['a','b','c','d']) series07.name = 'Series_name' series07.index.name = 'Series_indexName'
-
-
DataFrame:一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引(index)也有列索引(colum),可以被看做是由Series组成的字典。
DataFrame的行列表头均为索引
默认索引表头为下标值
df01 = pd.DataFrame[['joe','suan','andy'],[70,80,90]]
-
DataFrame创建
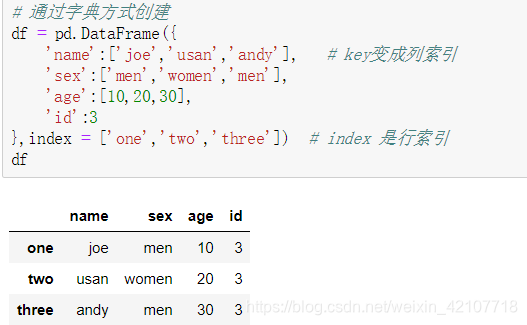
-
DataFrame索引
DataFrame分为行索引和列索引,默认情况下是从0开始,也可以自定义索引,添加行索引使用 index ,添加列索引使用 columns ,此操作称“重置行列索引值”
-
pandas中的loc-iloc-ix的使用
iloc是基于“位置”的dataFrame操作,i为下标值的意思,loc为location的缩写
# 使用DataFrame 和 iloc 进行单行/列的选择 # 行选择: data.iloc[0] # 数据中的第一行 data.iloc[1] # 数据中的第二行 data.iloc[-1] # 数据中的最后一行 # 列选择: data.iloc[:, 0] # 数据中的第一列 data.iloc[:, 1] # 数据中的第二列 data.iloc[:, -1] # 数据中的最后一列使用iloc注意:
- iloc只选择单独一行会返回series类型,选择多行会返回DataFrame类型
- 使用[1:5]这种语法进行数据切片时,满足左闭右开原则,仅包含下标1,2,3,4
loc则针对索引,DataFrame的表头来取值,同时可以使用布尔值/带条件查找
ix是早期pandas版本,现已经抛弃(2021)
-
DataFrame获取数据及其CRUD
可以直接通过列索引来获取指定列,但是获取指定行需要iloc或者loc
-
np.c_和np.r_
np.r_是按行连接两个矩阵,就是把两矩阵上下合并,要求列数相等。
np.c_是按列连接两个矩阵,就是把两矩阵左右合并,要求行数相等。
类似有vstack,hstack方法,对两个数组“拼接”
a=np.floor(10*np.random.random((2,2)))
b=np.floor(10*np.random.random((2,2)))
print(a),print(b)
print(np.vstack((a,b))) #vstack将数组a,b竖直拼接vertical
print(np.hstack((a,b))) #hstack将数组a,b水平拼接horizontal
vsplit,hsplit方法,对数组“切分”
a=np.floor(10*np.random.random((2,12)))
print(a)
print(np.hsplit(a,3)) #hsplit将数组a在水平方向切分成3等分
a1=np.floor(10*np.random.random((2,12)))
print(a1)
print(np.hsplit(a1,(3,4))) #hsplit将数组a在水平方向切分,从列索引3前切,到列索引4前停止
b=np.floor(10*np.random.random((12,2)))
print(b)
print(np.vsplit(b,3)) #vsplit将数组b在竖直方向切分成3等分
数组矩阵运算
矩阵A、B
A*B#对应元素乘积
A.dot(B)#使用dot矩阵乘积
数组整体函数操作
np.exp(B)#对数组B取e指数
np.sqrt(B)#取平方根
rabel方法,将数组维度拉成一维数组
a=np.floor(10*np.random.random((3,4)));print(a) [[1. 7. 8. 5.] [2. 4. 8. 4.] [7. 9. 1. 3.]]
print(a.ravel()) #ravel矩阵按行拉成一维数组 [1. 7. 8. 5. 2. 4. 8. 4. 7. 9. 1. 3.]
数组赋值后指向:直接赋值,浅复制,深复制
a=np.arange(12)
b=a
print(b is a) #赋值后,b和a指向同一个内存地址
b.shape=3,4
print('b维度变成(3,4)后a的维度:',a.shape)
print('a的id:',id(a));print('b的id:',id(b)) #取a,b在内存里的id
print('_________________________________')
c=a.view() #c是对a的浅复制,两个数组不同,但数据共享
print(c is a)
c.shape=2,6
print(a.shape); #c的形态变量,a的形态没变
print('对c赋值前的a:\n',a);
c[0,4]=1234;print('c:\n',c);print('对c赋值后的a:\n',a) #c的[0,4]位置数据改变,a也改变
print('_________________________________')
d=a.copy() #d是对a的深复制,两个数组不同,数据也不共享
print(d is a)
d[0,0]=9999
print('d:\n',d);print('a:\n',a)
print('+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++')
##在数组中找最大值的位置
import numpy as np
data=np.sin(np.arange(20)).reshape(5,4)
print('初始数据:\n',data)
index=data.argmax(axis=0) #argmax找每列的最大值位置
print('每一列最大值的索引:',index)
data_max=data[index,range(data.shape[1])] #根据索引index找出data数组里的元素!!!
print('根据索引找出最大值:',data_max)
print('直接办法取最大值:',data.max(axis=0)) #array.max(axis=0)
print('检测两种办法取到的max是否一致:',all(data_max==data.max(axis=0)))
print('+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++')
##对数组中元素“排序”
print('(1.)sort方法作用类np上<对象参数a不变,生成数组新开辟空间给b>:')
a=np.array([[4,3,5],[1,2,1]])
print('np.sort对a进行行排序前的a:\n',a)
b=np.sort(a,axis=1) #sort对数组a里的元素按行排序
print('对a进行行排序后的b:\n',b)
print('np.sort对a进行行排序后的a:\n',a)
print('a的id:',id(a));print('b的id:',id(b))
print('(2.)sort方法作用对象a上,a被改变:')
a.sort(axis=1)
print(a)
print('a的id:',id(a))
print('_________________________________')
#返回最大值的索引
aa=np.array([0.4,0.3,0.1,0.2])
print('初始aa数组:',aa)
j=np.argsort(aa)
print('对aa元素排序后的索引位置:',j)
print('根据索引的排序对aa重排:',aa[j])
print('+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++')
##对数组进行复制
a=np.arange(0,40,10)
print(a)
b=np.tile(a,(4,1)) #tile对a进行4行1列的复制
print(b)




